
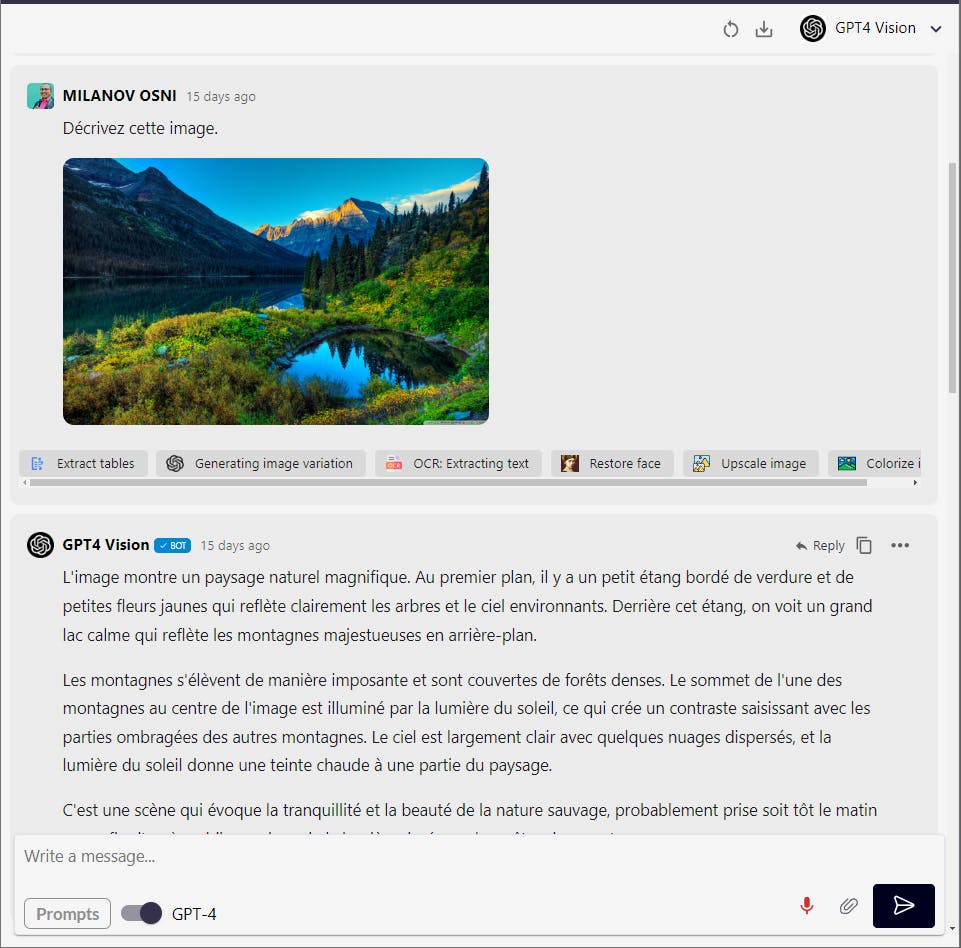
GPT4vision, interpret and analyze images
GPT-4V Turbo (GPT-4V) is a multimodal model developed by OpenAI. It allows the model to interpret and analyze images, not just text prompts, making it a "multimodal" large language model. GPT-4V can take in images as input and answer questions or perform tasks based on the visual content.


Découvrez la puissance de GPT4 Vision, l'IA de pointe de Swiftask qui étend les capacités de GPT-4 au domaine visuel. Avec son analyse d'image avancée et son système de réponse intuitif, GPT4 Vision simplifie l'interprétation, le catalogage et la compréhension des riches détails dans n'importe quelle image.
Fonctionnalités
- Reconnaissance d'objets : identifiez et étiquetez facilement divers objets dans une image.
- Reconnaissance de texte : extrayez et interprétez facilement du texte à partir d'images, des panneaux de signalisation aux menus.
- Reconnaissance des couleurs : détectez et nommez les couleurs, améliorant la compréhension de l'esthétique visuelle d'une image.
- Reconnaissance des formes : identifiez les formes géométriques, aidant à l'analyse structurelle des éléments visuels.
- Compréhension d'informations complexes : GPT4 Vision est équipé pour comprendre et gérer des entrées plus complexes, lui permettant d'offrir des réponses plus précises et pertinentes.
- Contrôle accru : GPT4 Vision donne aux utilisateurs une plus grande capacité à influencer le résultat généré, leur permettant d'orienter les réponses de l'IA vers le résultat souhaité.
Cas d'usage
- Éducation : créez des expériences d'apprentissage interactives en analysant des images historiques, des œuvres d'art, etc.
- Immobilier : évaluez les images de propriétés pour l'attrait visuel et la précision descriptive dans les annonces.
- Génération de contenu : produisez des articles, récits et contenus promotionnels engageants qui touchent votre public cible.
- Analyse de données : transformez des données complexes en rapports informatifs et facilement compréhensibles.
- Éducation et exploration : utilisez GPT4 Vision pour accélérer et faciliter la compréhension de nouveaux sujets ou langues.
Comment l'utiliser ?
1- Cliquez sur le bouton "Commencez maintenant" ci-dessous pour accéder à la plateforme.
2- Importez une image ou engagez une conversation directe avec GPT4 Vision.
Mise à jour
Date : 20/03/2024
Il est maintenant possible d'importer vos documents sur GPT4 Vision pour les faire traiter par l’IA.
category