How to extract the tables contained in a pdf document?
When working with PDF files, it is often necessary to extract precise data to manipulate and organize them. Among these data, tables are among the most commonly extracted elements. If you are looking for a solution to easily extract tables from PDF files, the Swiftask app is here to help.
Ready to transform your business with AI?
Discover how AI can transform your business and improve your productivity.
The usefulness of table extraction work
Extracting tables from a PDF is a useful task in many situations. It converts tabular data contained in PDF files into more flexible and usable formats. The following uses can make you understand what is the use of extracting tables from PDF in a smart way.
For fast and efficient data analysis
Extracting tables from PDF files makes it possible to collect tabular data from various sources such as reports, surveys or financial statements. This makes it easier to analyze and explore the data to draw conclusions or identify trends. By using array extraction tools, it is possible to retrieve this data efficiently and use it in other programs for further analysis.
To make business reports
Companies often produce reports in PDF format containing important data in the form of tables. Extracting these tables can help summarize and visualize key information more easily, which helps in making a good decision. By using Swiftask's table extraction tool it is possible to retrieve this data regardless of its end use.
For further academic research
Extracting tabular data from scientific articles or publications is a common practice for researchers. This allows them to retrieve important data for analysis, comparison with other studies, or inclusion in their own research. With Swiftask's bot, researchers can retrieve this data and use it to further their understanding of a topic or to support their own conclusions.
Conversion to editable formats
Extracting tables from PDF files converts data into editable formats such as CSV (comma separated values) or Excel. This makes it easier to manipulate the data later, as these formats are widely used and can be easily imported into other programs for more detailed analysis. Extraction can also help identify trends or patterns in the data.
Preparing data for visualization
Before creating graphs or visualizations from data contained in a PDF file, it is often necessary to extract the raw data from a table to format and prepare it. This can help speed up processes and reduce human error, allowing businesses to process important elements contained in PDF files.
Financial Data Extraction
In finance, bank statements, balance sheets, and other financial reports are often available in PDF format. Extracting tables from these documents can facilitate financial analysis and data management. This allows finance professionals to easily manipulate data to perform analysis, create charts or visualizations, or update databases. Table mining can therefore be a valuable tool for finance professionals looking to save time and improve their work efficiency.
Steps for extracting tables from a PDF with Swiftask
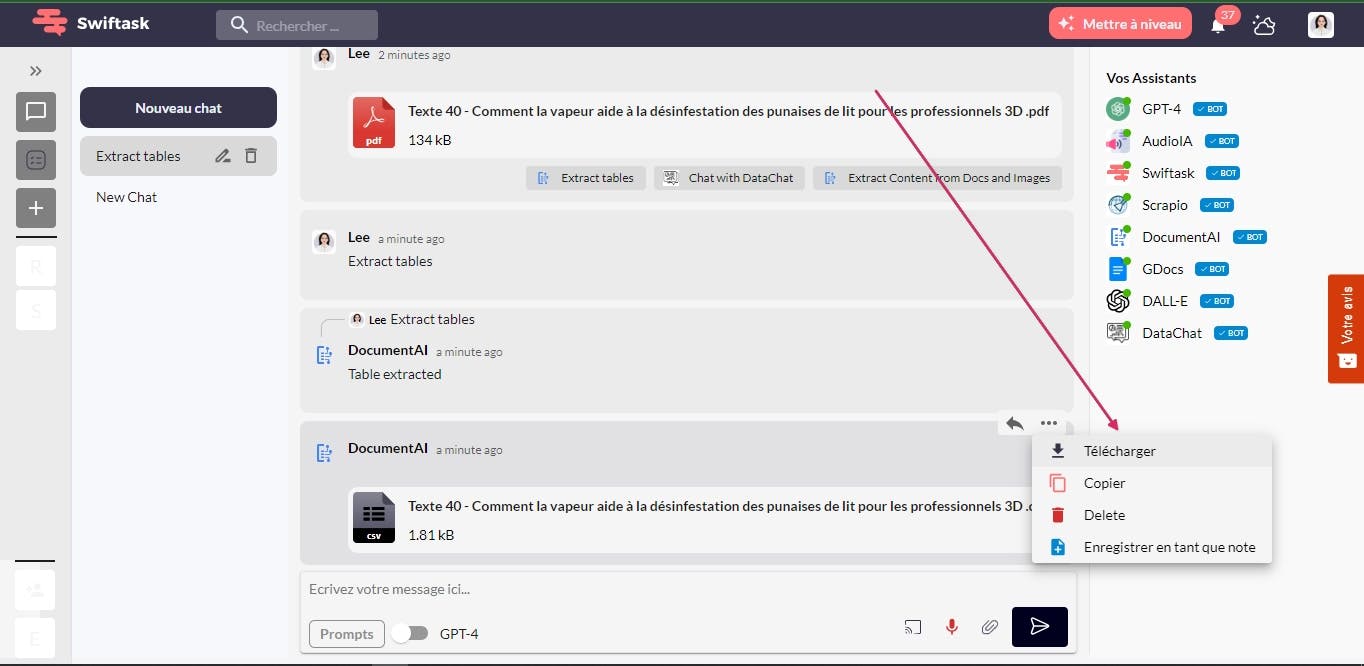
1- To use the Swiftask app, navigate to the app on your device (computer, tablet, smartphone, etc.) and open it. You will have access to all available functions, including table extraction.
2- To import a file into the Swiftask app, click the import attachments option in the message bar. Select the file you want to import, then press the Send button to import it into the app.
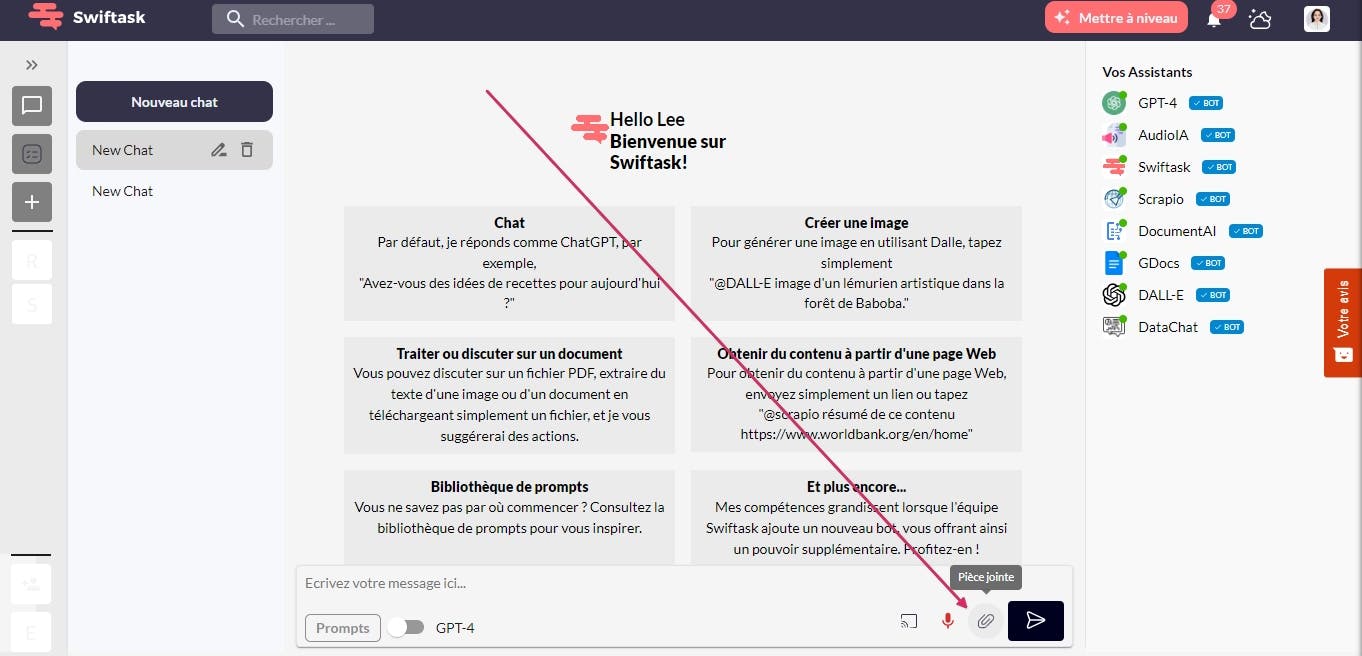
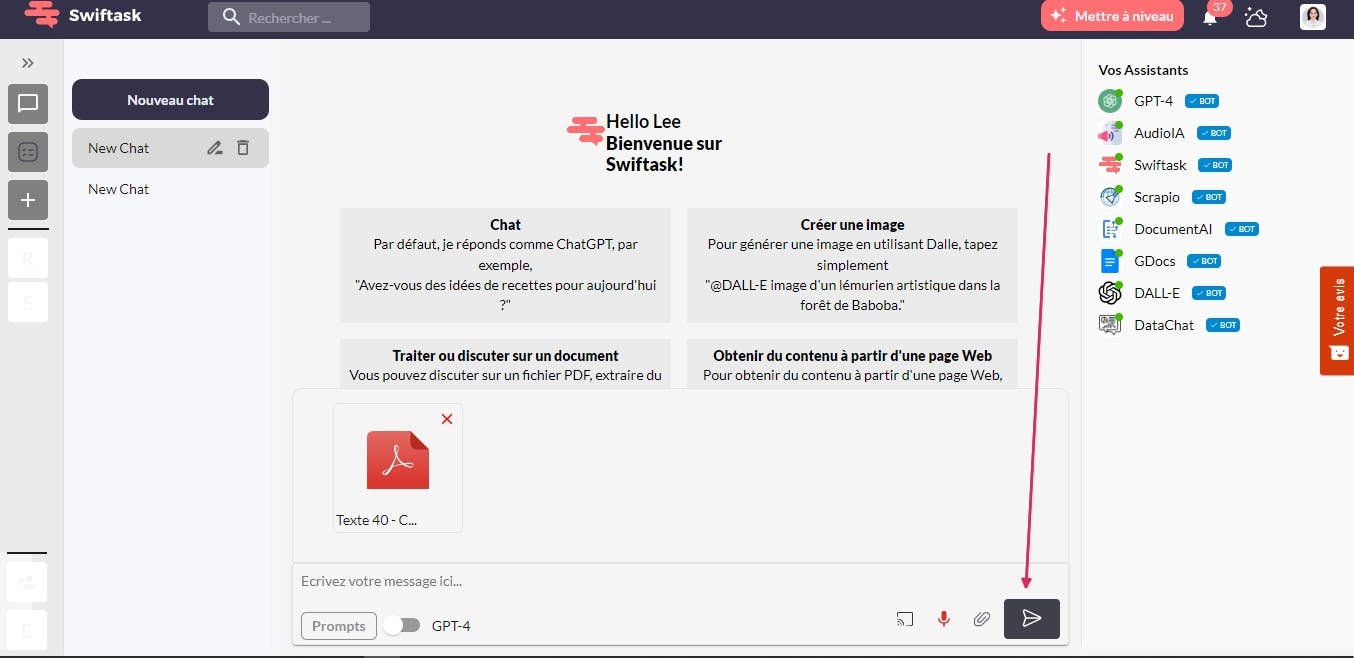
3- Once you have imported the file into the Swiftask application, click on the "Extract Tables" option to extract the tables from the file. It's that simple.
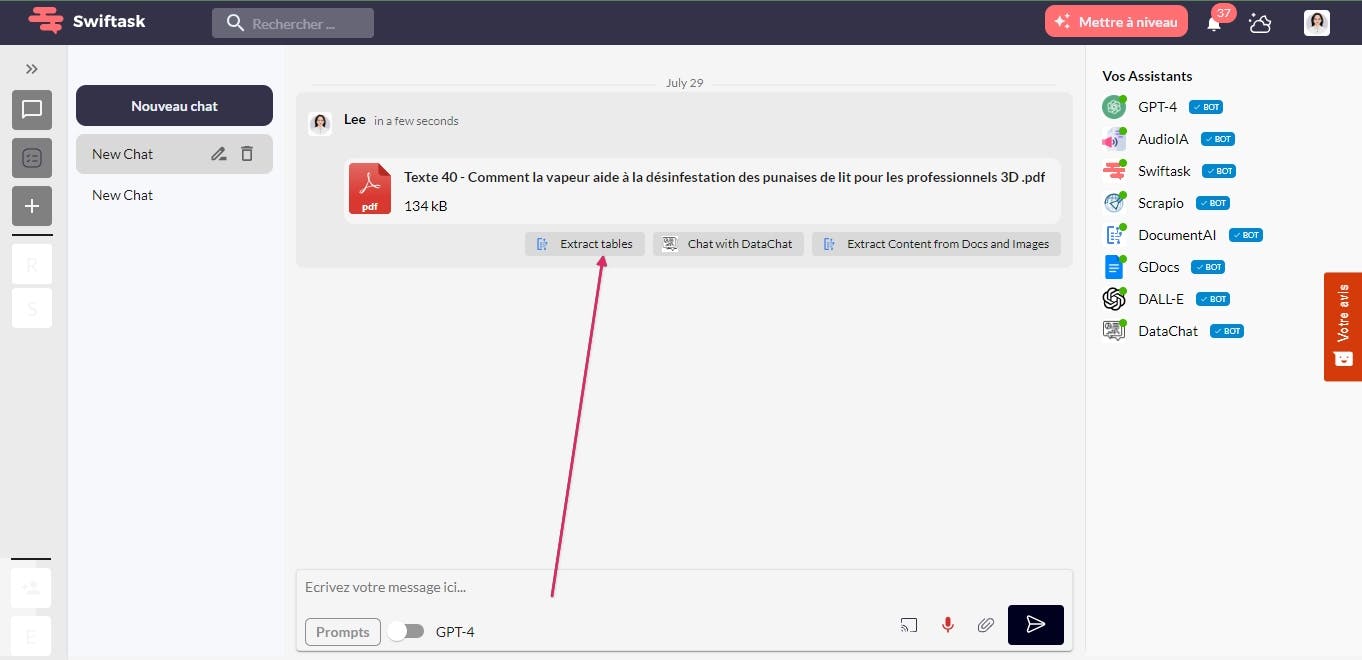
4- After extracting the tables from the file using the Swiftask application, you will receive a new file in CSV format. This file contains the data extracted from the tables in the original file.
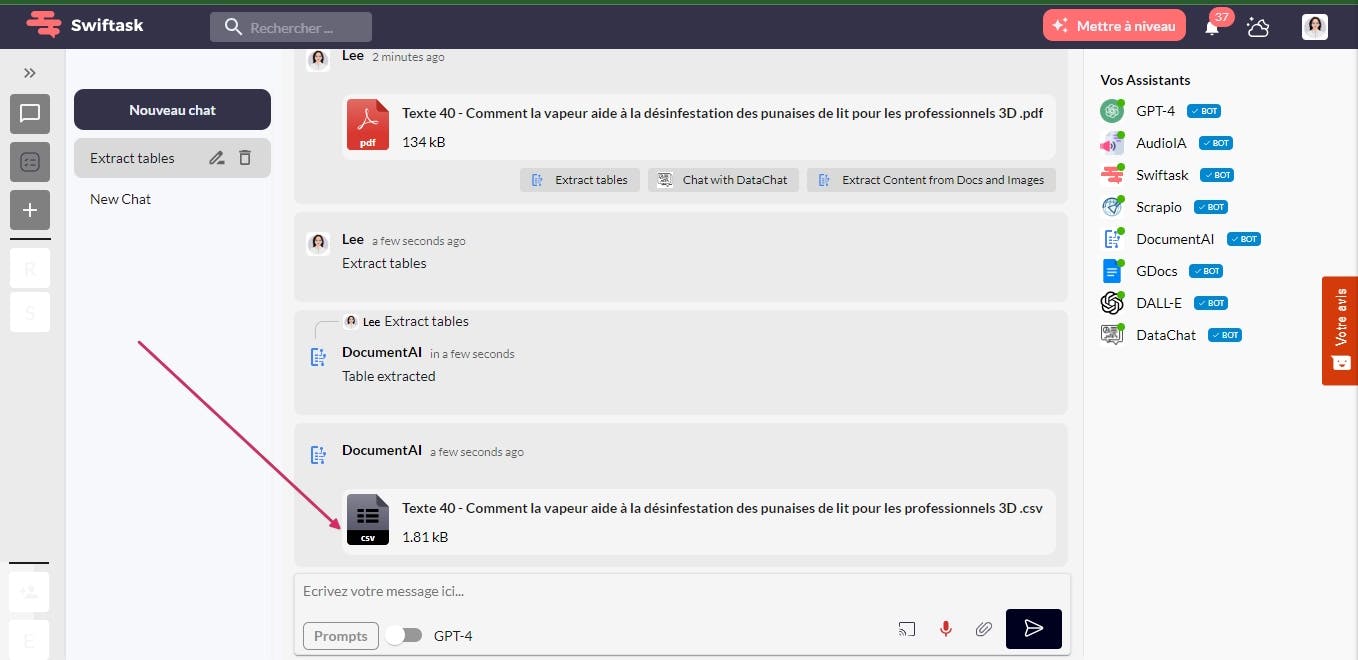
5- Once you have received the CSV file containing the data extracted from the tables using the Swiftask app, you can download it to use in your work. This file can be easily imported into other programs for further analysis or to create graphs and visualizations.
Benefits of Swiftask for Extracting table
Time saving
Using the Swiftask app to extract tables from a PDF file can save you a lot of time and effort. By automating this process, you can free up time to focus on other important tasks. Swiftask lets you quickly retrieve important data from tables in a PDF file.
Accuracy
Swiftask's Table Extractor tool can extract data with high accuracy, reducing typing errors that can occur when entering data manually. It can help you save time and improve your work efficiency.
Productivity
Using artificial intelligence to extract tables from a PDF file can increase your business productivity. By automating this process, your employees can focus on more important tasks rather than wasting time on manual, repetitive tasks. This can improve your business efficiency by allowing your employees to work on more complex projects and make informed decisions based on accurate and easily accessible data.
Easy analysis
Data obtained from tables in a PDF file can be easily analyzed and used to create reports, charts and other visualizations. This makes it possible to obtain precise information in real time from the data contained in the tables.
In short, Swiftask is a user-friendly and powerful application that allows you to work efficiently with PDF files, including extracting tables. Whether you need to retrieve financial data, research data, or any other type of tabular data, Swiftask gives you a quick and easy solution for extracting tables from PDF files.
author
OSNI

Published
July 31, 2023
Ready to transform your business with AI?
Discover how AI can transform your business and improve your productivity.