
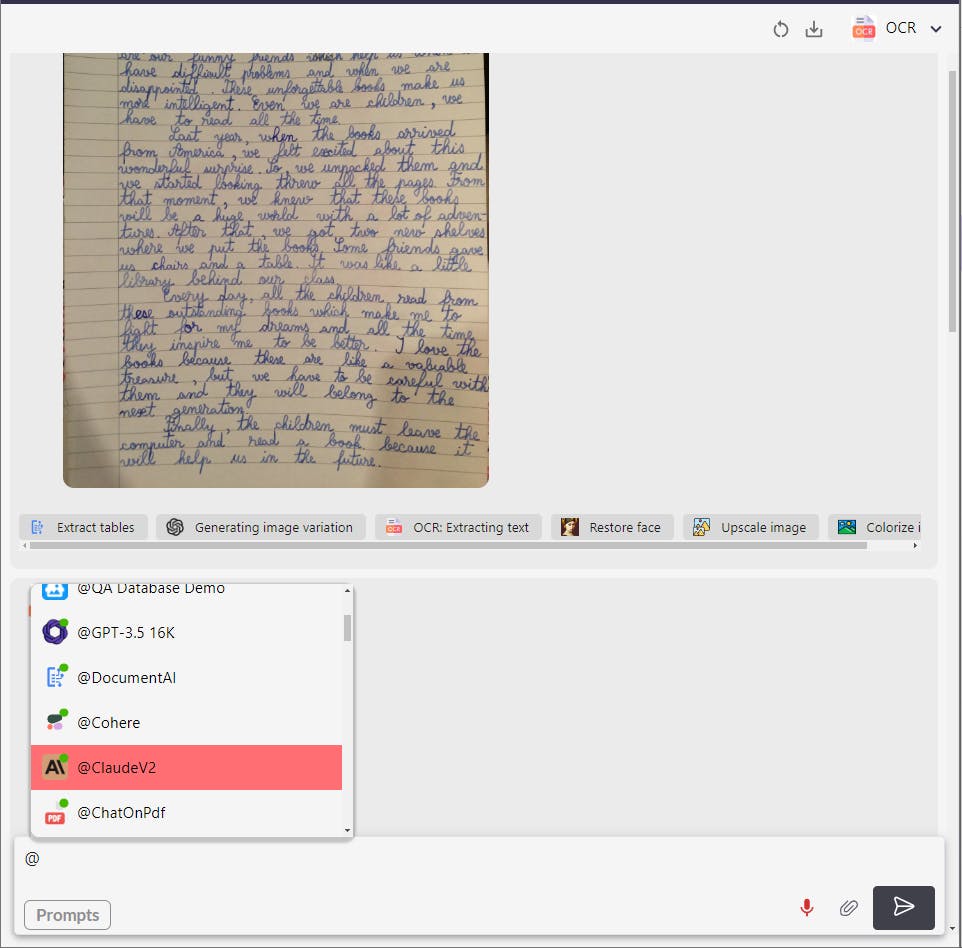
OCR allows extracting text from scanned images, PDFs or handwritten documents, and you can then interact with the extracted text. To get started, please upload the image or document you want to extract text from.

Unlock the full potential of your documents with the Swiftask OCR (Optical Character Recognition) Tool. This powerful feature transforms images, PDFs, and docx files into editable and interactive text, allowing for seamless integration and further processing with Swiftask's suite of AI tools. Dive into endless possibilities as you discuss directly with the extracted content and handle multiple files simultaneously, even those of considerable size. Say goodbye to manual data entry and welcome a streamlined workflow with Swiftask OCR.
Features
- Multi-Format Support: Accepts input from image, PDF, and docx file formats for versatility.
- AI Integration: Ready for post-processing with other Swiftask AI tools for enhanced productivity.
- Interactive Content: Enables direct conversation with the extracted text for immediate clarifications and commands.
- Bulk Processing: Processes several files at once for efficient batch operations.
- Large File Handling: Capable of managing large files without a compromise in speed or accuracy.
Practical use cases
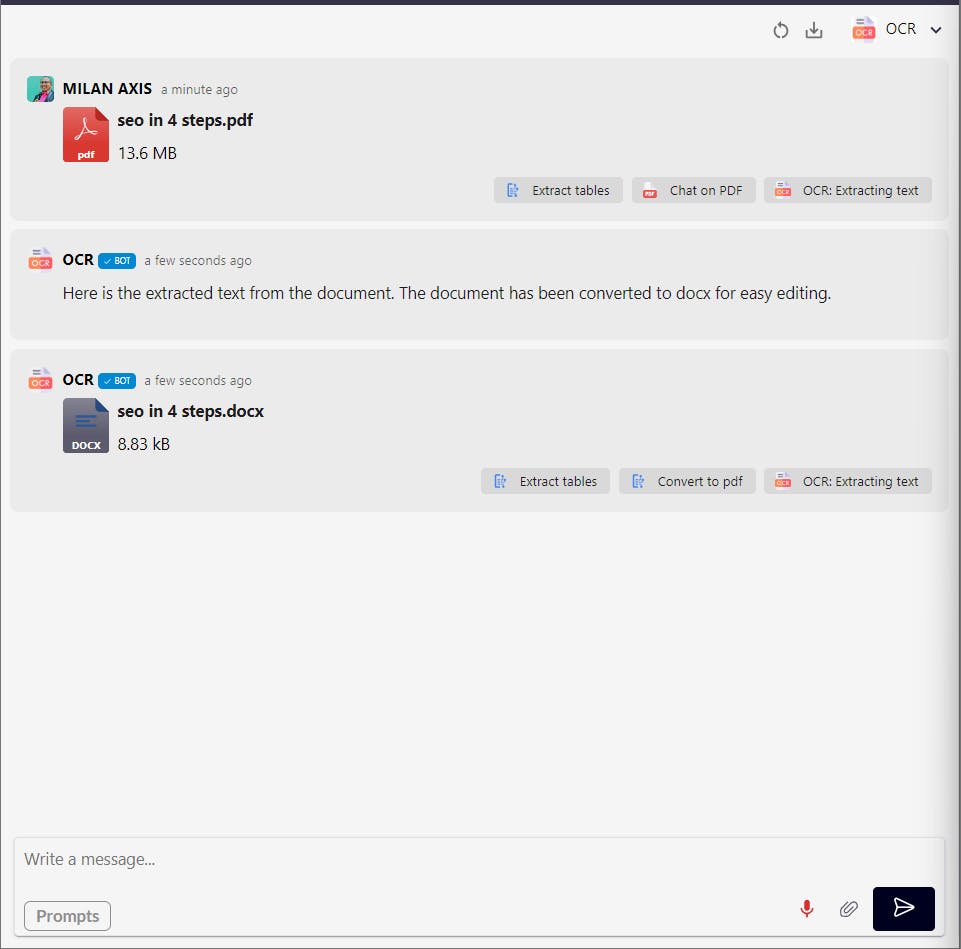
- Digitize a stack of printed documents into editable files for data analysis or archiving.
- Turn a batch of business reports in PDF format into actionable datasets that can be directly queried.
- Extract text from high-resolution scans for digital content curation or content management systems.
- Discuss with the extracted contents to quickly locate information or execute commands within the digitized text.
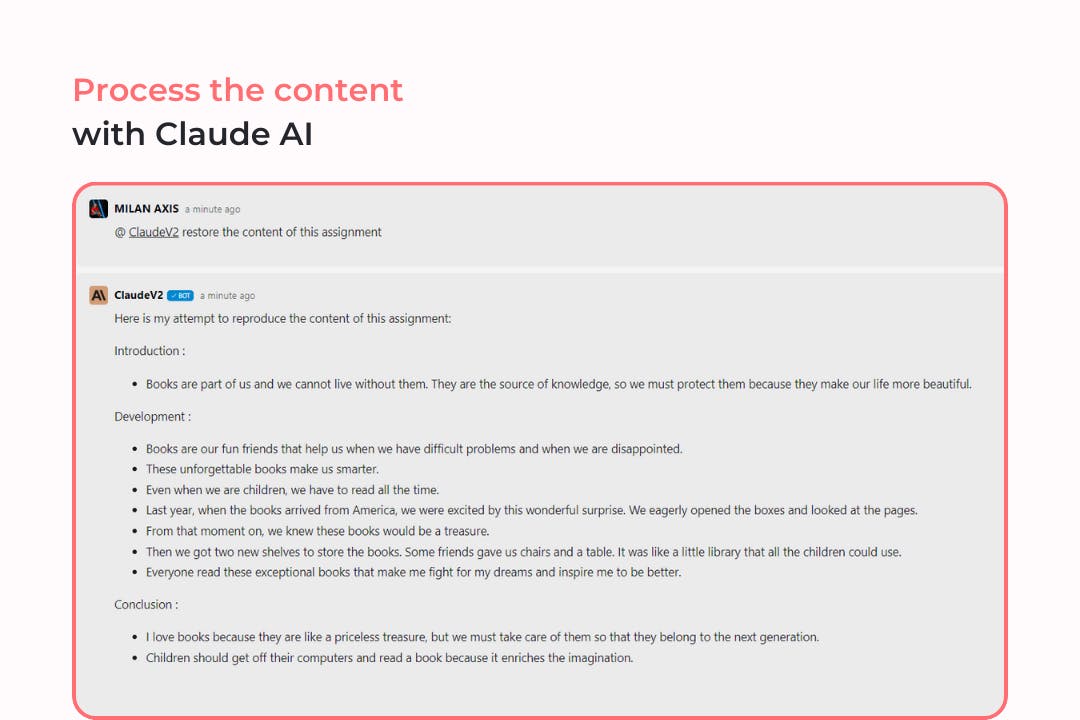
Combining with other AIs
To analyze the OCR results with the AI of your choice on Swiftask, simply access the chat bar, type "@", select your desired AI, and then enter your prompt.
How to use it ?
1- Click on the "Get Started" button below to access the platform.
2- Import the file containing the data to be extracted and continue processing its content.
category