
GPT4vision, interpret and analyze images
GPT-4V Turbo (GPT-4V) is a multimodal model developed by OpenAI. It allows the model to interpret and analyze images, not just text prompts, making it a "multimodal" large language model. GPT-4V can take in images as input and answer questions or perform tasks based on the visual content.
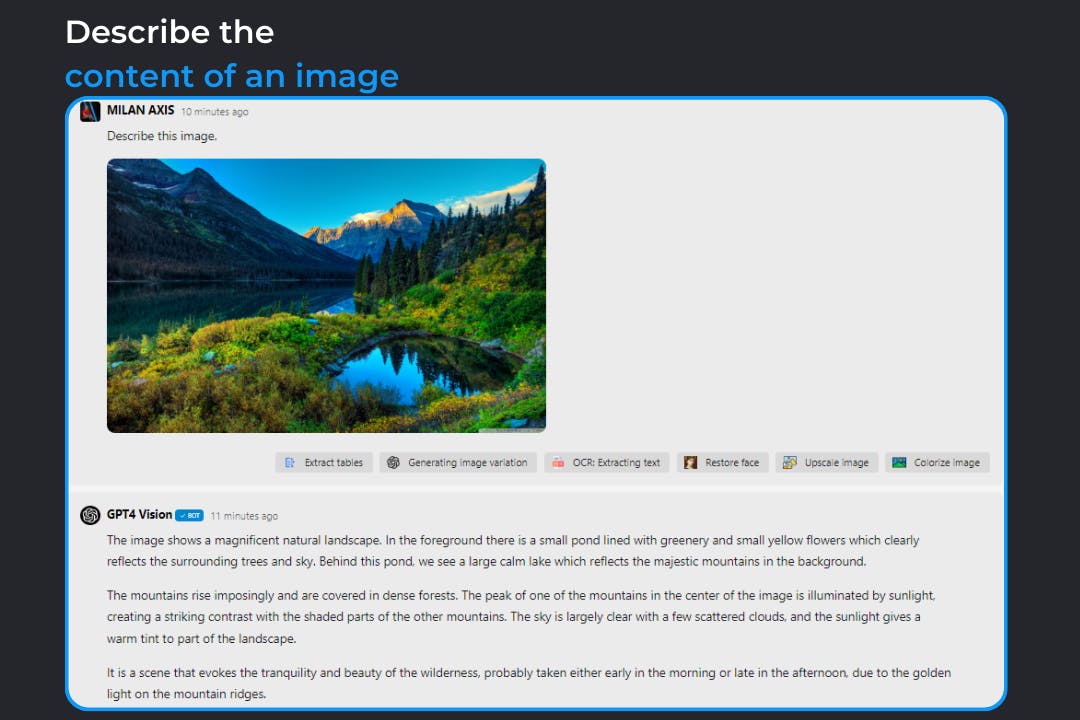
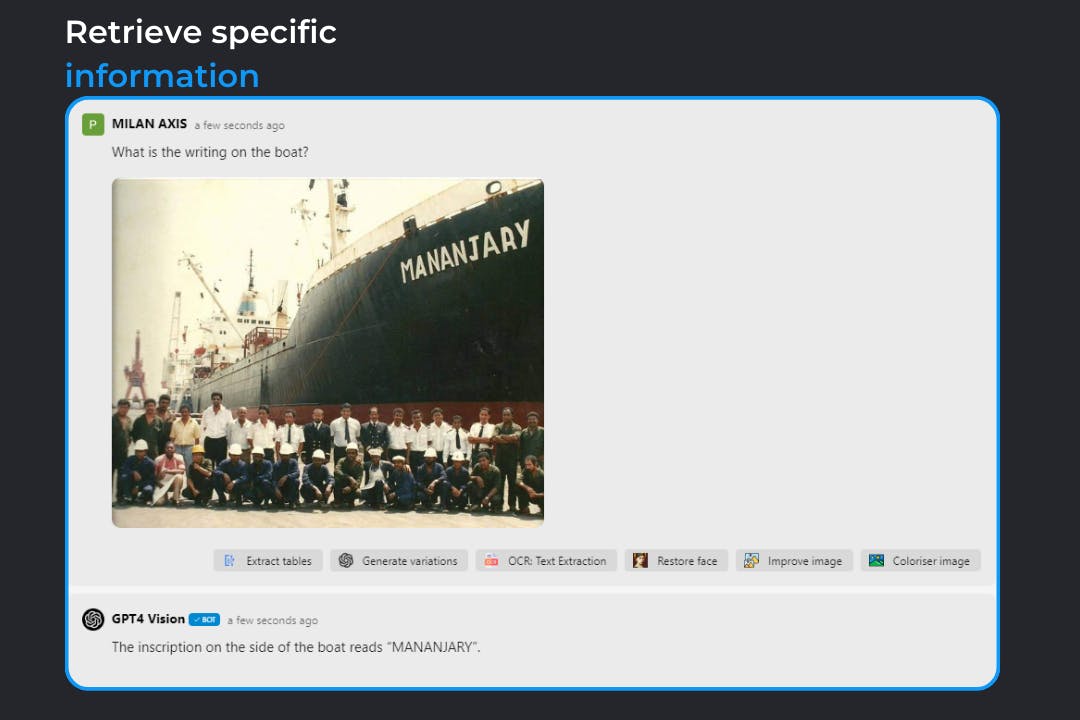
Discover the power of GPT4 Vision, the cutting-edge AI from Swiftask that extends the capabilities of GPT-4 to the visual realm. With its advanced image analysis and intuitive response system, GPT4 Vision makes it simple to interpret, catalog, and understand the rich details within any image.
Features
- Object Recognition: identify and label various objects within an image with ease.
- Text Recognition: effortlessly extract and interpret text from within images, from street signs to menus.
- Color Recognition: detect and name colors, enhancing understanding of visual aesthetics in an image.
- Shape Recognition: identify geometric shapes, aiding in structural analysis of visual elements.
- Comprehending intricate information: GPT4 Vision is equipped to comprehend and handle more intricate inputs, allowing it to offer more precise and pertinent responses.
- Increased control: GPT4 Vision gives users a greater ability to influence the generated output, allowing them to direct the AI's responses toward a desired outcome.
Practical use cases
- Education: create interactive learning experiences by analyzing historical images, art, and more.
- Real Estate: assess property images for visual appeal and descriptive accuracy in listings.
- Content Generation: produce engaging articles, narratives, and promotional content that connects with your target audience.
- Data Analysis: transform intricate data into informative, easily comprehensible reports.
- Education and Exploration: utilize GPT4 Vision to expedite and facilitate the comprehension of new subjects or languages.
How to use it?
1- Click on the "Get Started" button below to access the platform.
2- Import an image or engage in direct conversation with GPT4 Vision.
Update
Date: 20/03/2024
It is now possible to import your documents onto GPT4 Vision for processing by AI.
category